
We track the questions that matter, show how models describe and cite you and point to the exact page edits that increase trustworthy visibility.
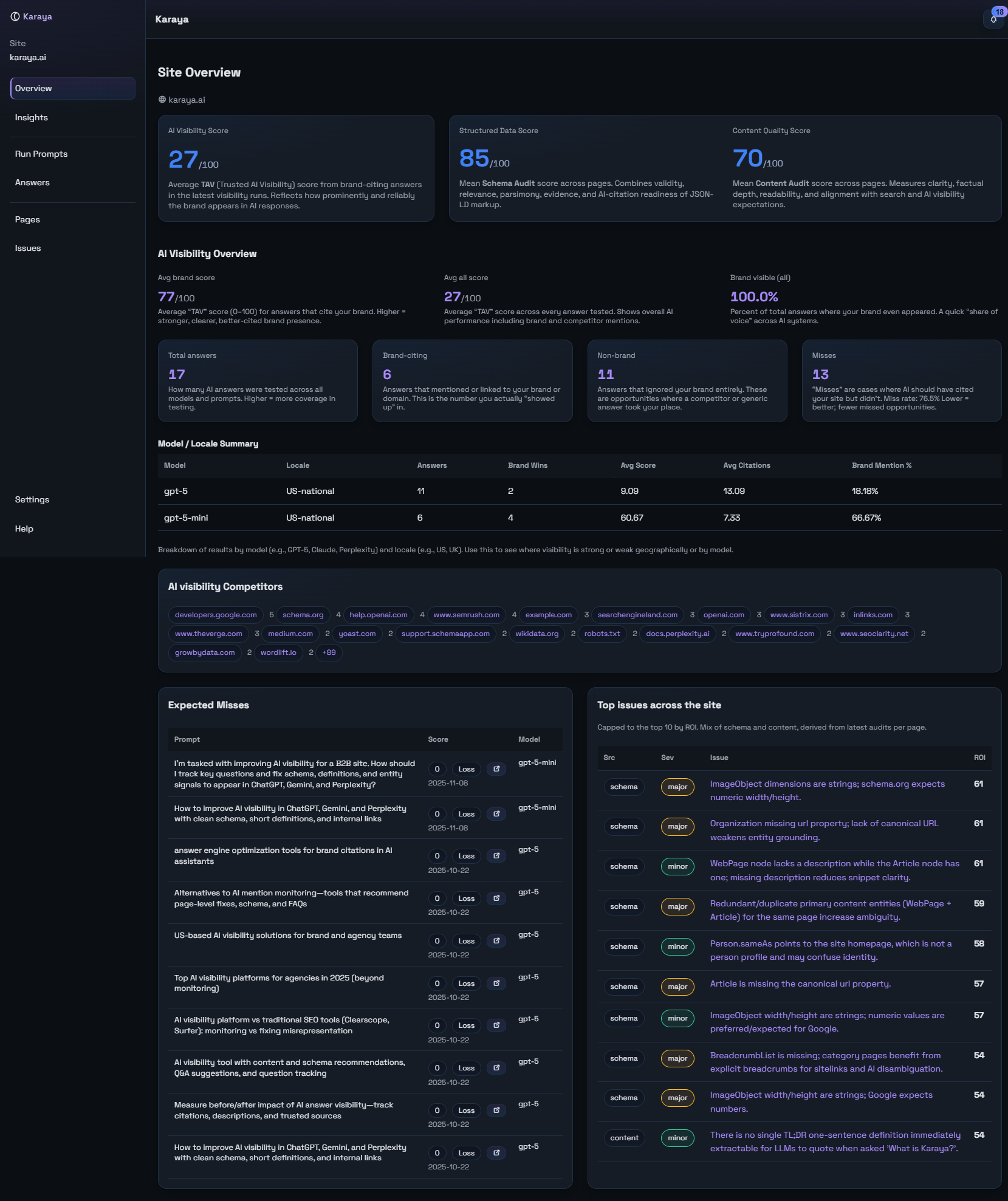
Track key questions, see model answers and the page fixes that move citations.
How it works
1) Track key questions
We monitor real questions your audience asks AI tools. Not keyword lists. Questions in plain language, by topic and locale.
- Prompt sets organized by funnel or use case
- Scheduled runs across multiple models
- Each answer stored with its sources
2) See your current standing
We show how often your brand is named, when your site is cited and which sources models lean on. You see wins, losses and where the wrong page was used.
- Mentions, citations and “best-fit page” checks
- Competitor vs authority source balance
- Stability over time by model and locale
3) Fix what AI needs
We turn missed or weak answers into a short to-do list. It’s page-level work: tighten a definition, add a fact, clean JSON-LD or link to the right subpage.
- Short definition at the top of the page
- Q&A or facts block for scannability
- Correct schema types and key properties
- Links to pricing, docs, FAQ or contact
4) Measure the effect
Run a small cohort, make edits, rerun. You see before/after visibility for the same questions so progress is clear and repeatable.
- Time-series for mentions, citations and alignment
- Missed citation recovery over time
- Snapshotted HTML to tie changes to outcomes
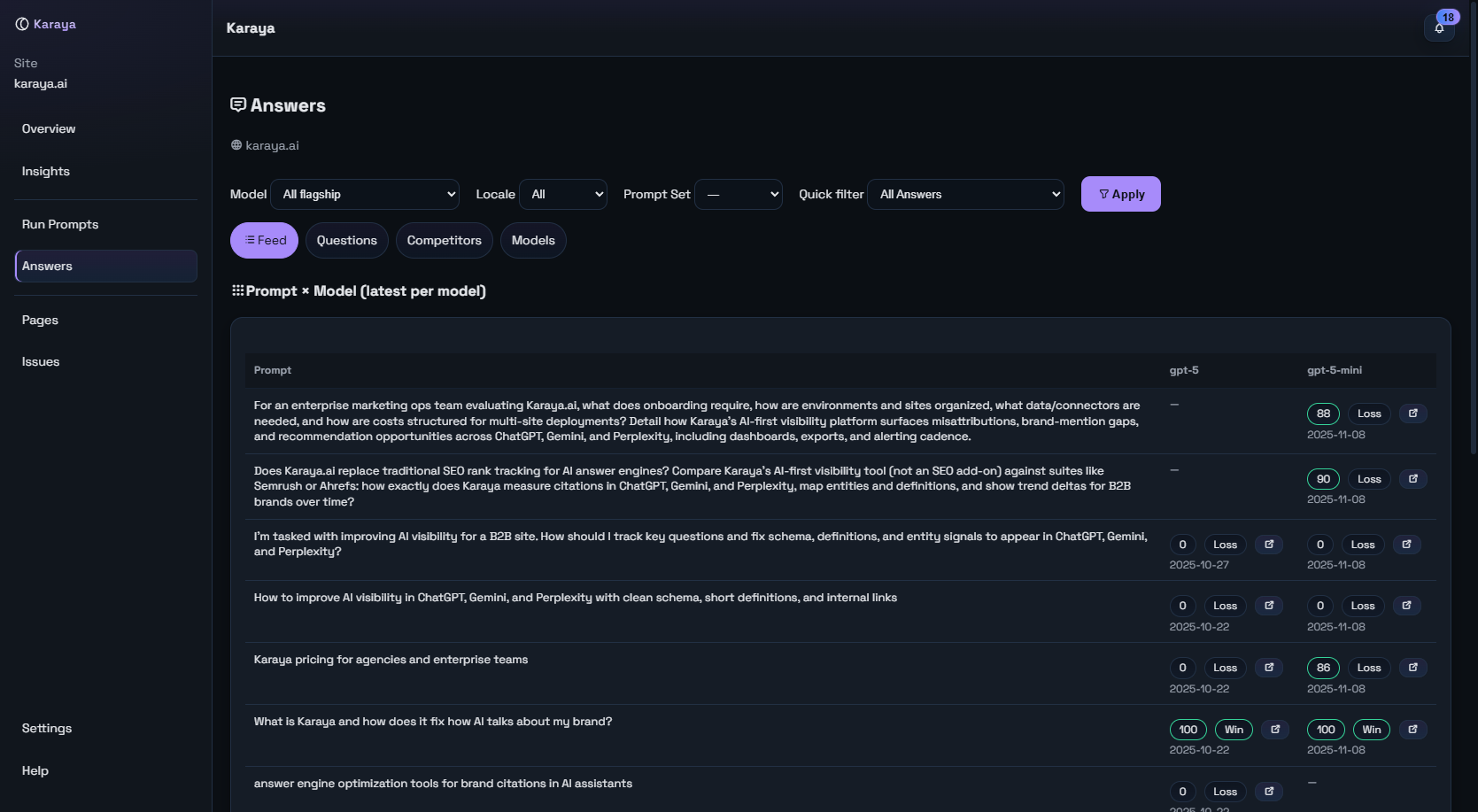
See what the model said, who it cited and why your page did or didn’t earn the link.
What “good” looks like in AI answers
AI answers are not binary wins or losses. One “win” can be stronger than another. A citation can still send readers to the wrong page. Karaya grades the quality of a result so you can push beyond “mentioned” to “trusted and useful.”
- Mentioned: The answer names your brand clearly.
- Cited: Your domain appears in the citations.
- Aligned: A cited URL is the best subpage for the question intent.
- Quality matters: Earlier mention, clearer coverage, balanced sources and recent context all make a stronger result.
Why we use a composite score: AI visibility is nuanced. We summarize strength across mention, citation, alignment, evidence and risk. It keeps progress honest and directional without hiding what changed.
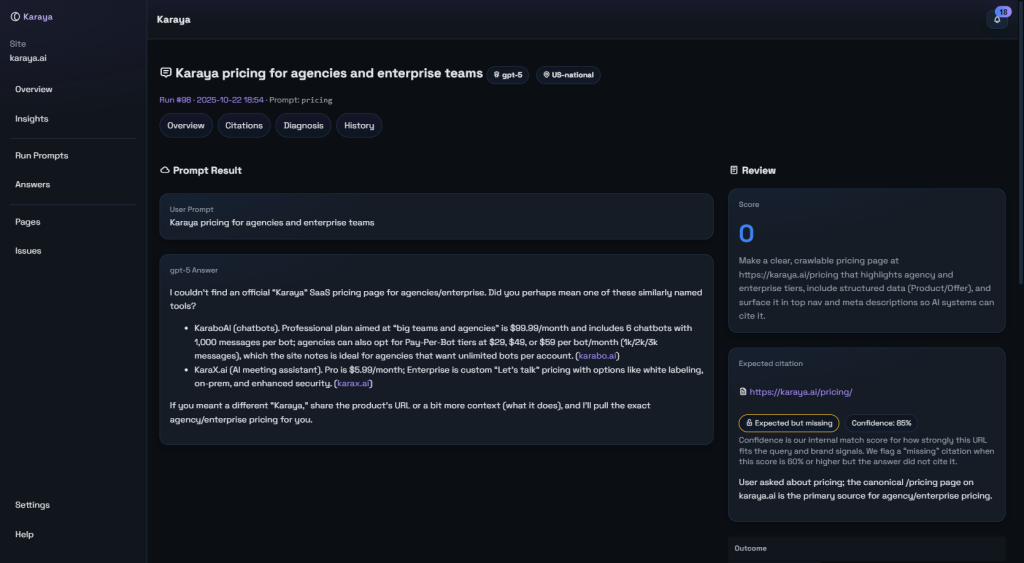
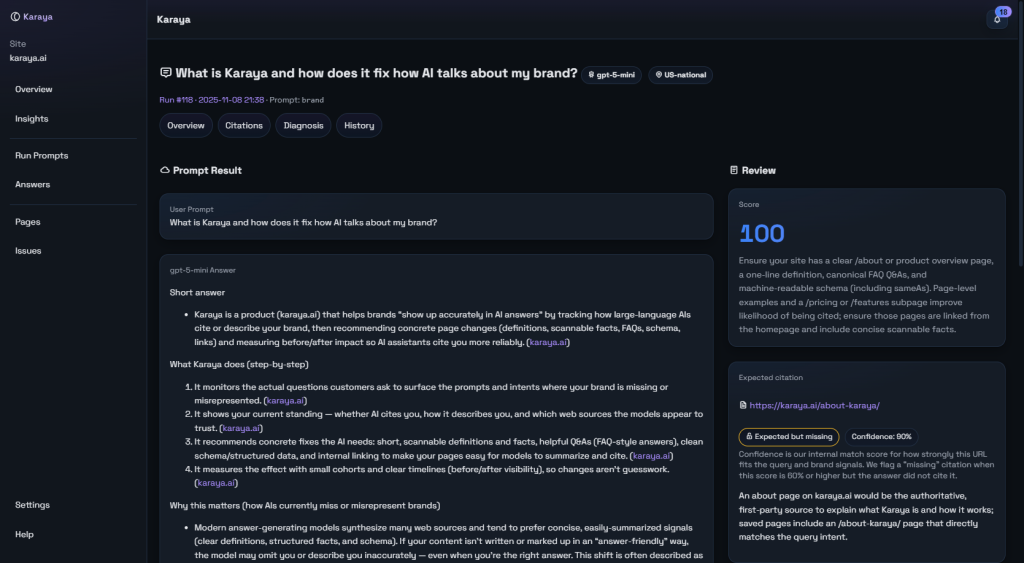
Why one result beats another—clear coverage, the right page, stronger sources.
From audit to action
Karaya focuses on page fixes that change how models write and cite. We prefer specific edits over generic advice.
- Clarify scope: One-line definition near the top.
- Make it scannable: Short Q&A or facts block.
- Point to the right place: Internal links to pricing, docs, FAQ.
- Clean schema: Correct types and key properties.
Priority is driven by impact. First recover likely citations you should have earned, then fix pages used by valuable questions, then address template-level issues that repeat.
- Missed likely citations
- Wrong-page citations (homepage vs best subpage)
- Recurring schema gaps across templates
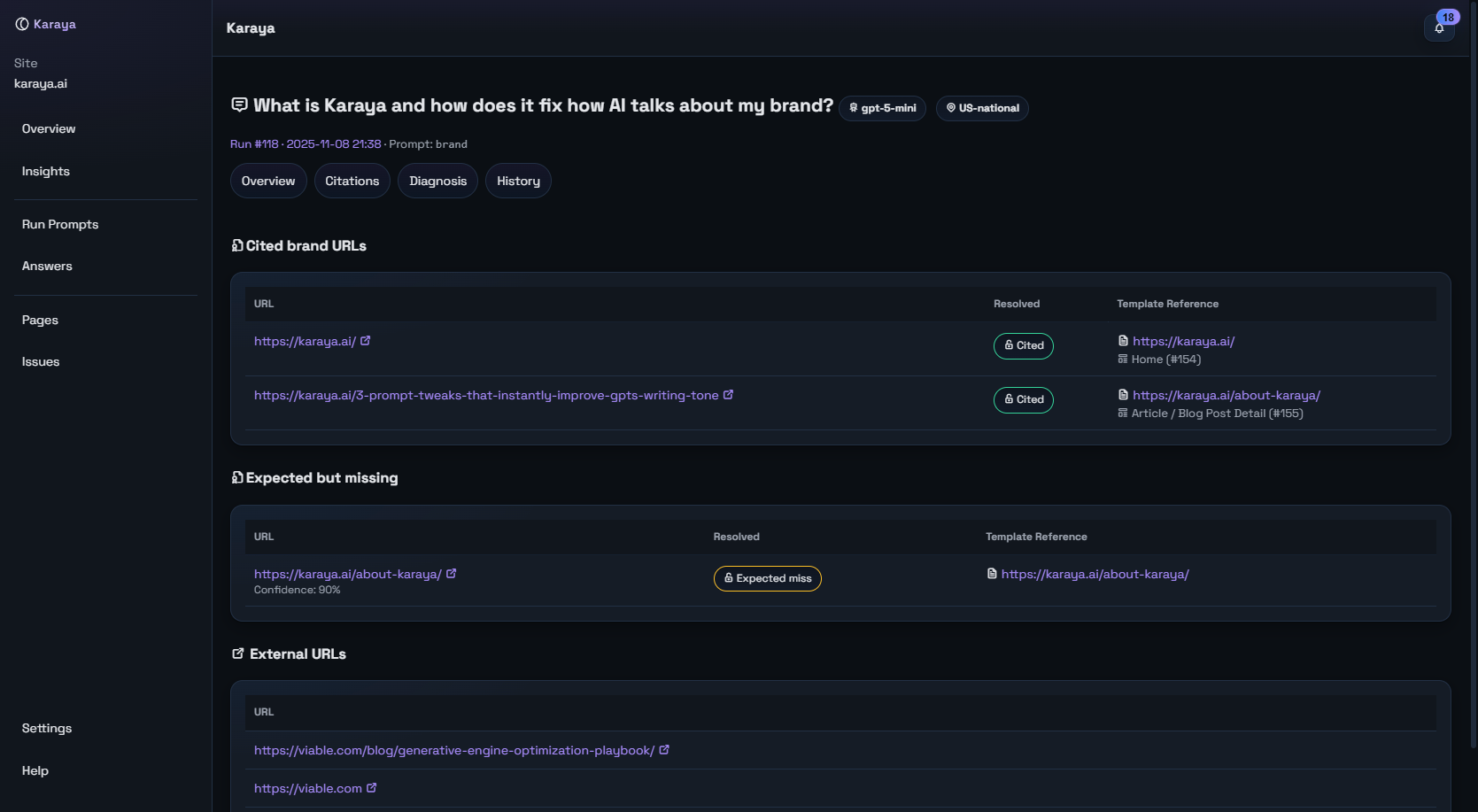
Which sites the model trusts for this topic and whether your URL is the best fit.
Competitor context without the guesswork
We break down which sources models favor for your topics and why. If a competitor earns the citation you want, Karaya shows the gap and the page changes that close it.
- Which domains are cited and how often
- Where your brand is named but not cited
- Where the wrong page is cited from your site
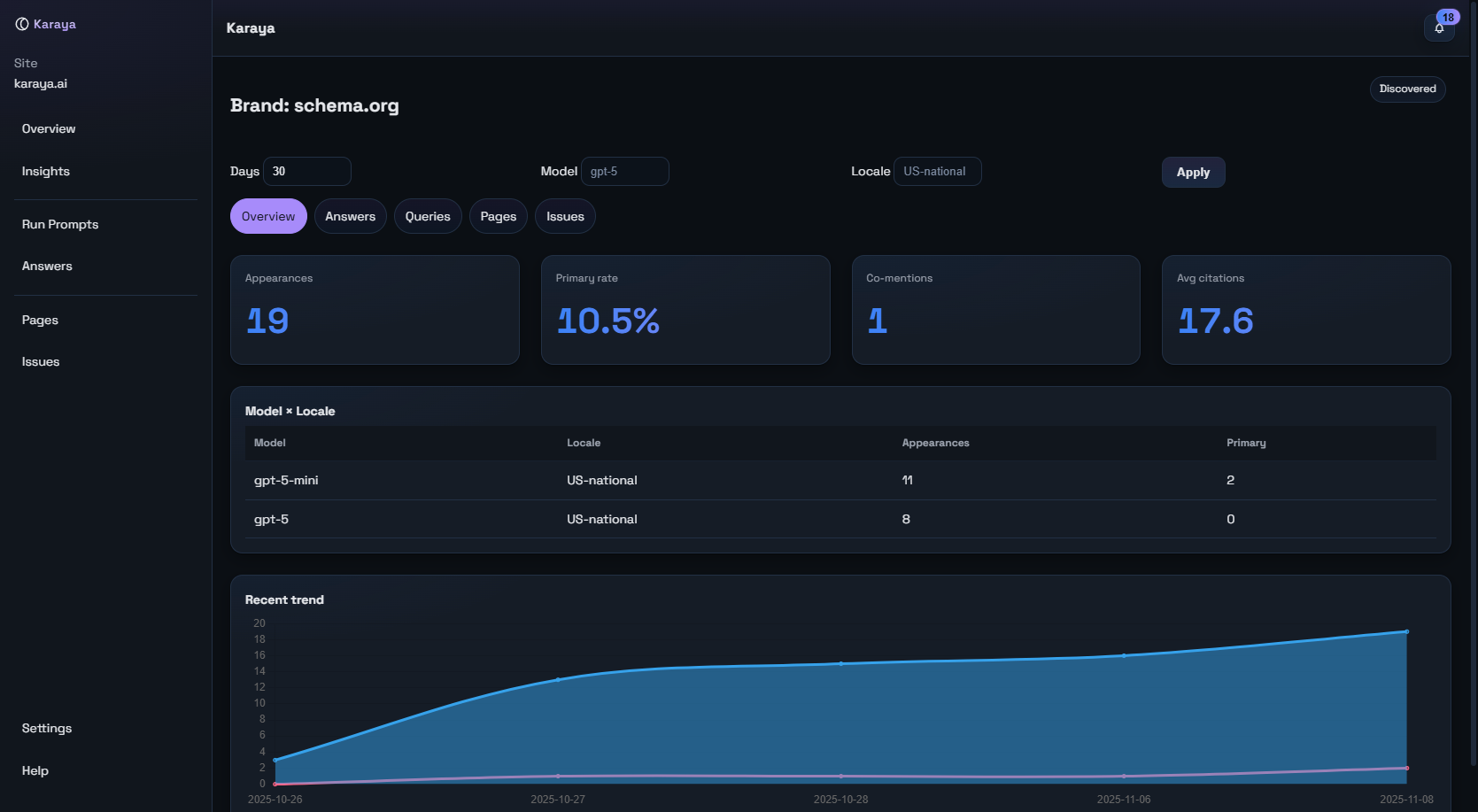
Where rivals win citations you should own and what to change to reclaim them.
A simple, repeatable workflow
- Select a small set of questions that matter.
- Run the models your audience actually uses.
- Apply the top three page fixes.
- Rerun and compare. Keep what moves the needle.
Everything is tied to stored page snapshots so you can see exactly what changed and which edit correlated with better answers.
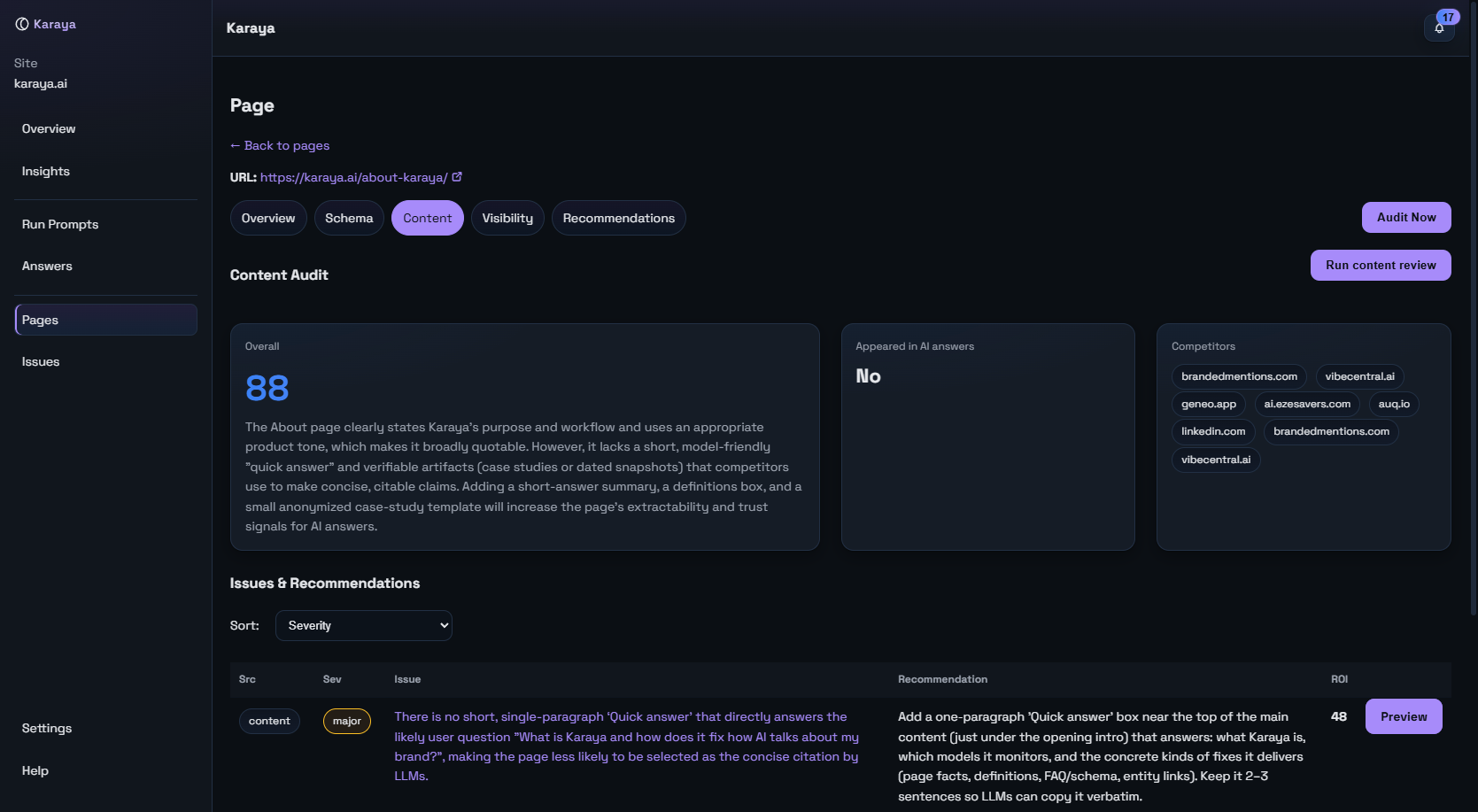
The exact edits that make this page citation-ready.
FAQ
Is this SEO with AI bolted on?
No. We measure what AI models say and cite today, then fix pages to influence those answers.
What if my brand is mentioned but not cited?
We flag likely citations you should win and show the page changes that earn them.
Do I need schema?
Clean JSON-LD helps models verify facts. We show the exact properties to add.
How do you show progress?
We compare the same questions before and after edits, tied to stored snapshots.
How do we start?
Pick ten core questions. Run a baseline. Make three targeted page edits. Rerun and review.
How technical is this?
Non-technical teams can run prompt sets. Edits map to clear fields in your CMS or JSON-LD.
Make AI answers include the right page
Track the questions that matter, fix what AI needs and measure the lift.